과제/팀과제
[Django] 최종 프로젝트 : 지금은 전시상황!(7) - [BE]추천 시스템 상세글 조회에 연결하기
마이구미+
2023. 6. 16. 20:01
<모델 수정>
- 데이터 불러오기
# exhibitions/recommendation_ml.py
import psycopg2, os
# 데이터베이스 연결
con = psycopg2.connect(
host=os.environ.get("DB_HOST"),
dbname=os.environ.get("DB_NAME"),
user=os.environ.get("DB_USER"),
password=os.environ.get("DB_PASSWORD"),
port=os.environ.get("DB_PORT"),
)
cur = con.cursor()
cur.execute("SELECT id, info_name, location, category From exhibitions_exhibition")
cols = [column[0] for column in cur.description]
exhibition_df = pd.DataFrame.from_records(data=cur.fetchall(), columns=cols)
con.close() # 데이터베이스 연결 종료- 우리의 데이터가 데이터베이스로 들어가면서 csv 파일을 불러오는 방식에서 데이터베이스에서 데이터를 불러오는 방식으로 바꿨다
- 관련 내용은 어제 TIL에 작성했다
230615 팀프로젝트[TIL]
- 소셜(구글) 로그인 수정 백엔드와 통신하는 함수 중 한 줄짜리 간단한 get요청을 개별 js 파일에 넣었었는데 아무래도 api.js로 다 빼는 게 좋지 않을까 하는 피드백이 와서 그걸 수정했다 함수를
guco.tistory.com
- 유사도 측정
# exhibitions/recommendation_ml.py
# info_name별 유사도 측정
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2))
info_name_mat = count_vect.fit_transform(exhibition_df["info_name"])
# 유사도 행렬 생성
info_name_sim = cosine_similarity(info_name_mat, info_name_mat)- 데이터 불러오는 방식이 바뀌면서 5번째 줄이 수정됐다
- data -> exhibition_df
- 서비스명 -> info_name
- 이름만 바뀐 셈이다
- 추천 함수
# exhibitions/recommendation_ml.py
import numpy as np
...
# 특정 정보와 서비스명 유사도가 높은 서비스 정보를 얻기 위한 함수 생성
def recommendation(id, top_n=10):
# 입력한 정보의 index
target_info_name = exhibition_df[exhibition_df["id"] == id]
target_index = target_info_name.index.values
# 입력한 정보의 유사도 데이터 프레임 추가
exhibition_df["similarity"] = info_name_sim[target_index, :].reshape(-1, 1)
# 유사도 내림차순 정렬 후 상위 index 추출
temp = exhibition_df.sort_values(by=["similarity"], ascending=False)
temp = temp[temp.index.values != target_index] # 자기 자신 제거
final_index = temp.index.values[:top_n]
raw_exhibitions = exhibition_df.iloc[final_index]
# print(raw_exhibitions)
ml_recommend_exhibitions_id_list = list(
np.array(raw_exhibitions[["id"]]["id"].tolist())
)
return ml_recommend_exhibitions_id_list- 원래는 데이터프레임 형식을 반환했는데 아예 함수 내에서 데이터 후처리까지 해서 추천된 전시회의 id 값 리스트를 반환하는 것으로 수정했다
<상세글 조회 시 추천글 같이 띄우기>
- views.py
# exhibitions/views.py
class ExhibitionDetailView(APIView):
def get_permissions(self):
if self.request.method in ["PUT", "DELETE"]:
return [IsAdminUser()]
return [IsAuthenticatedOrReadOnly()]
def get(self, request, exhibition_id):
exhibition = get_object_or_404(Exhibition, id=exhibition_id)
recommend = [
get_object_or_404(Exhibition, id=id) for id in recommendation(exhibition_id)
]
# query_params를 serializer로 전달
serializer = ExhibitionDetailSerializer(
exhibition,
context={
"select": request.query_params.get("select", None),
"request": request,
"recommend": ExhibitionSerializer(recommend, many=True).data,
},
)
return Response(serializer.data)- 원래 있던 상세 게시글 조회 부분에 recommend 필드를 추가했다
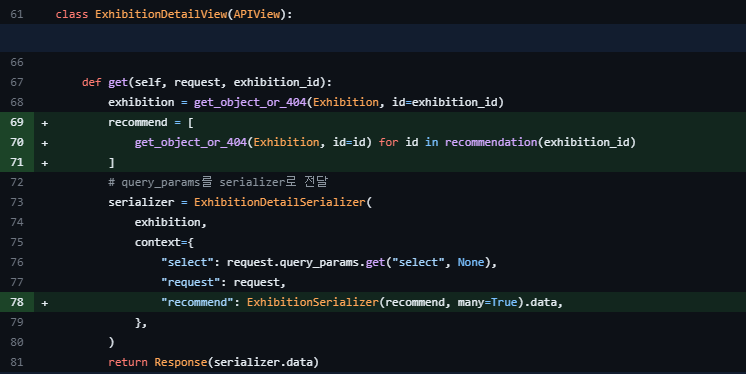
- 추가된 부분은 위와 같다
- recommendation() 함수에서 반환된 id 리스트를 for문을 돌려서 하나씩 객체를 불러오고 그걸 리스트로 만든다
- serializer 필드에 context 부분에 recommend라는 key를 추가하고 value로 ExhibitionSerializer로 직렬화해서 데이터를 담는다
- 여기서 오류때문에 잠시 수렁에 빠졌었는데 시리얼라이저에 many=True 옵션 주는 걸 깜빡했었다 ㅋㅋㅋ휴..
- serializers.py
# exhibitions/serializers.py
data["recommend"] = self.context["recommend"]- 시리얼라이저에는 단 한 줄 추가된다
- views.py에서 context에 담은 데이터를 직렬화 되는 필드를 생성해서 담아준다
- 전체를 확인해 보면 아래와 같다
- 추가된 부분은 12번째 줄에 있다
# exhibitions/serializers.py
class ExhibitionDetailSerializer(serializers.ModelSerializer):
"""전시회 상세보기"""
likes = serializers.SerializerMethodField()
# 읽기 전용 직렬화
def to_representation(self, instance):
# serializer.data
data = super().to_representation(instance)
data["recommend"] = self.context["recommend"]
pagination = CustomPageNumberPagination()
# query_params
select = self.context["select"]
# select에 따라 field 추가
if select == "accompanies":
accompany = instance.accompanies.all()
paginated_accompanies = pagination.paginate_queryset(
accompany, self.context["request"]
)
serializer = AccompanySerializer(paginated_accompanies, many=True)
data["accompanies"] = pagination.get_paginated_response(serializer.data)
else:
reviews = instance.exhibition_reviews.all()
paginated_reviews = pagination.paginate_queryset(
reviews, self.context["request"]
)
serializer = ReviewSerializer(paginated_reviews, many=True)
data["reviews"] = pagination.get_paginated_response(serializer.data)
return data
class Meta:
model = Exhibition
exclude = []
def get_likes(self, obj):
return obj.likes.count()- 결과
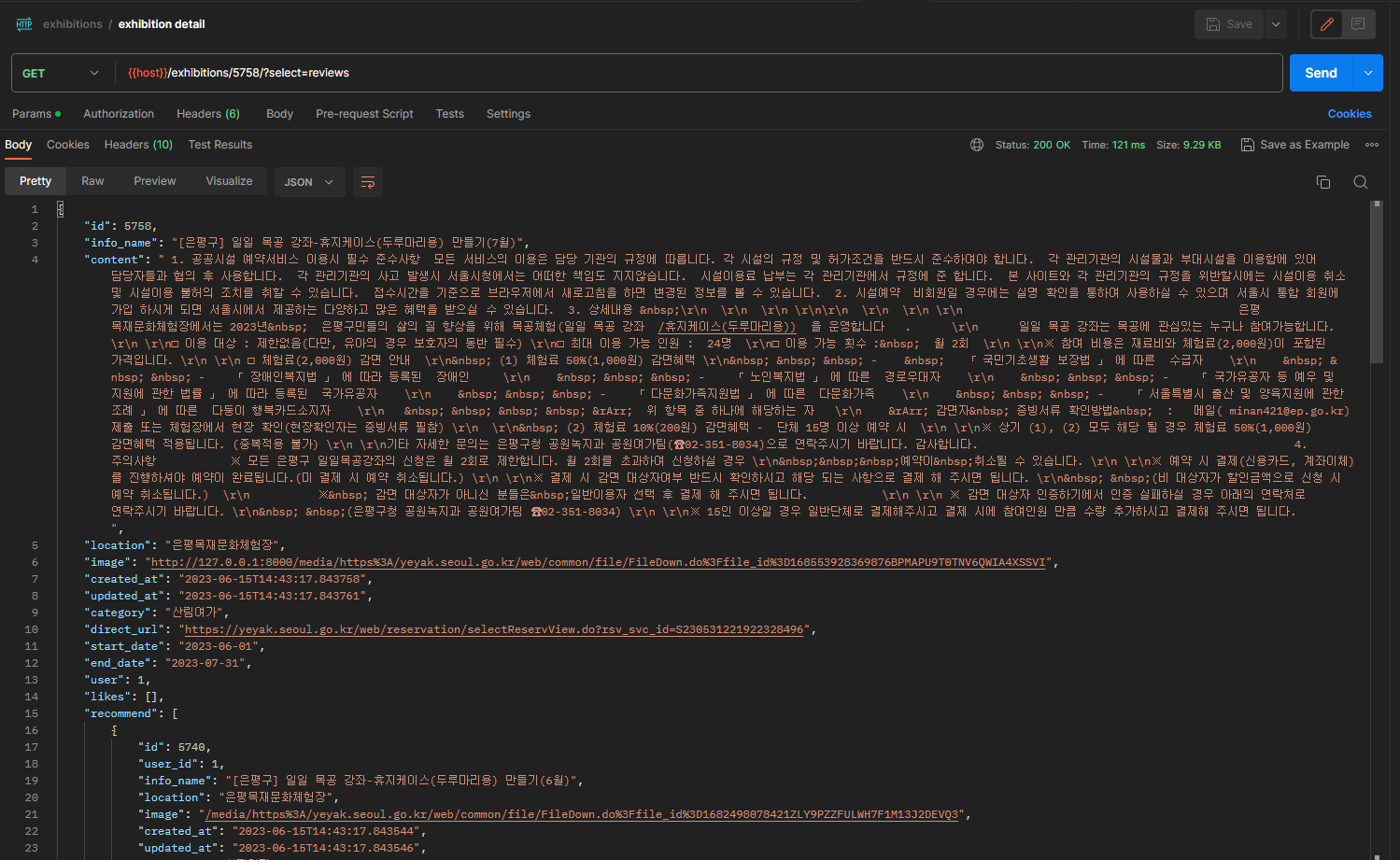
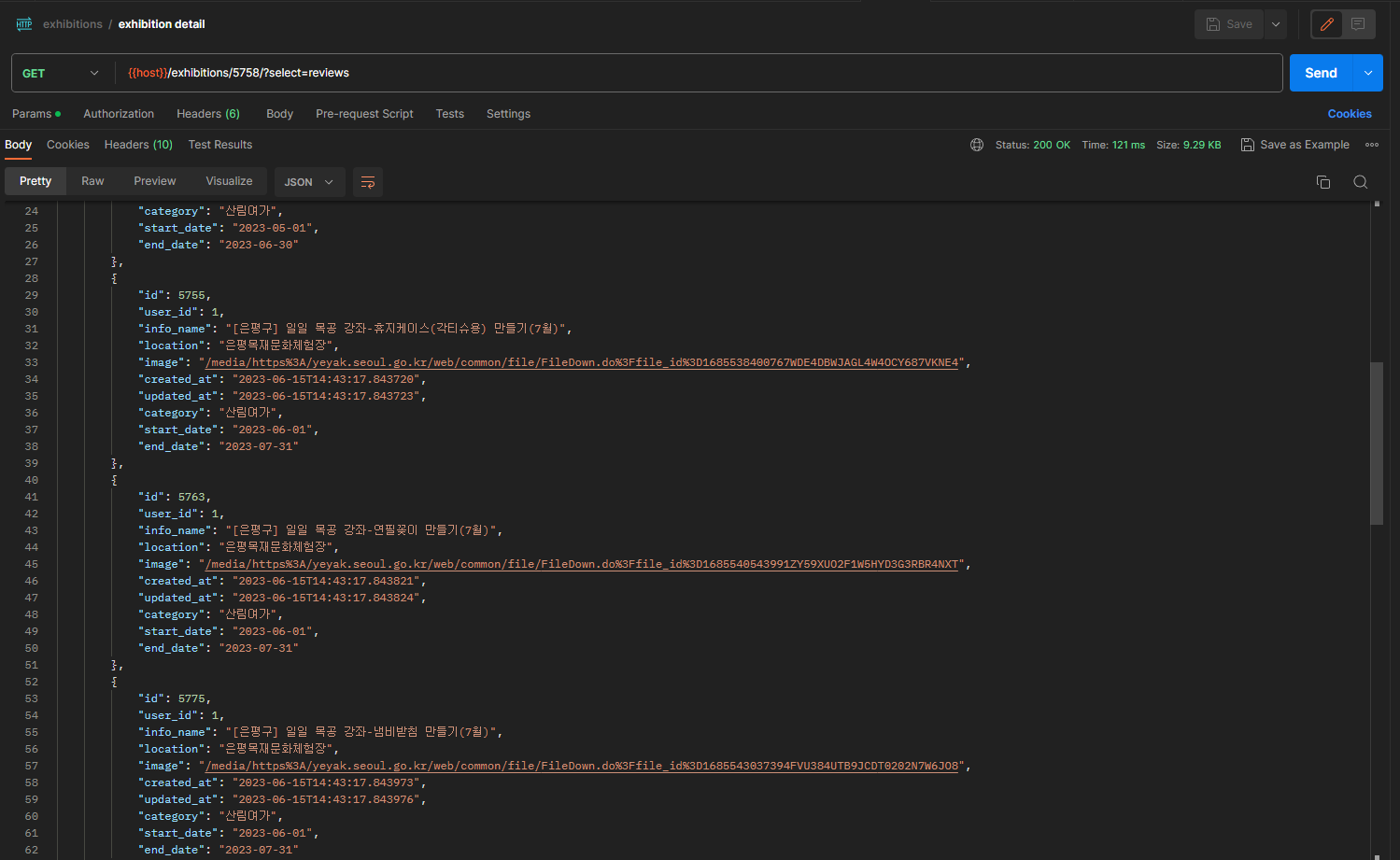

- 이렇게 상세게시글을 조회하면 비슷한 글 10개가 같이 조회된다