
<모델링>
근데 모델링이 맞는건가.....?....??...?
- 블로그를 참고해서 colab에서 진행했다
- csv 파일은 여기에서 다운받아 이름을 'seoul_culture_event_information'로 바꾼 후 colab 세션 저장소에 업로드 했다
- 겪은 오류들을 그대로 쭉 기록할 예정이다
파이썬과 함께 추천 시스템(recommendation system) 이해하기 기본편 - content based filtering
포스팅 개요 해당 글에 대한 코드는 아래 github 링크에 전부 올려두었습니다. https://github.com/lsjsj92/recommender_system_with_Python lsjsj92/recommender_system_with_Python recommender system with Python. Contribute to lsjsj92/rec
lsjsj92.tistory.com
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
- 데이터 전처리
패키지 로드
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity데이터 불러오기
data = pd.read_csv('seoul_culture_event_information.csv')- 여기서 에러가 났다
에러1
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-3-7bff6433d945> in <cell line: 1>()
----> 1 data = pd.read_csv('seoul_culture_event_information.csv')
10 frames
/usr/local/lib/python3.10/dist-packages/pandas/_libs/parsers.pyx in pandas._libs.parsers.raise_parser_error()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 1: invalid start bytedata = pd.read_csv('seoul_culture_event_information.csv', encoding='cp949')- 이렇게 수정하니 에러가 뜨지 않았다
row와 column 개수 보기
data.shape
# 출력화면
# (614, 24)- 614개의 데이터와 24개의 카테고리가 있다
data 변수에 필요한 column만 담기
data = data[['소분류명','서비스명','서비스대상']]- 리스트가 두 겹으로 쌓여있는데 리스트 하나만 있으면 에러가 뜬다
에러2
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3801 try:
-> 3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
4 frames
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ('소분류명', '서비스명', '서비스대상')
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
-> 3804 raise KeyError(key) from err
3805 except TypeError:
3806 # If we have a listlike key, _check_indexing_error will raise
KeyError: ('소분류명', '서비스명', '서비스대상')서비스명 인덱스 0부터 50까지 출력하기
data['서비스명'][:50]0 [대면] 2023년 <느낌 있는 박물관> 교육생 모집 안내
1 [백인제가옥] 2023년 온라인교육 '백인제가옥의 숨겨진 비밀을 찾아라!&#...
2 퀘벡영화의 날
3 [백인제가옥] 2023년 온라인교육 '백인제가옥의 숨겨진 비밀을 찾아라!&#...
4 백인제가옥 전시해설 예약(2023)
5 2023년 목편만들기(매주 일 14:00~16:00)
6 2023년 미니장승만들기(매주 토 10:30~12:30)
7 2023년 미니솟대만들기( 매주 토 14:00~16:00)
8 2023년 짚공예 체험(매주 일요일 10:30~12:30)
9 (수) 다함께 차차차(茶茶茶) (성인)
10 [청계천박물관] 초4~6학년 학급단체 교육 <졸졸졸 개천, 콸콸콸 준천>...
11 [청계천박물관] 2023년 상반기 온라인 교육 <톡톡톡 청계천> 참여기관 모집
12 순례역사길 1코스
13 [청계천박물관] 초3~6학년 주말 가족 교육 <우리는 청계천 탐험대> (토)
14 [청계천박물관] 초등 특수학급 단체 교육 <오감으로 만지는 청계천이야기>...
15 [청계천박물관] 유아 단체 교육 <꼬물꼬물 청계천 보물찾기> (목)
16 [청계천박물관] 2023년 6월 개방형교육 <우리들의 친구, 청계천박물관>...
17 [청계천박물관] 6월 유아가족교육 <청계천에서 들려주는 자연생태동화> 모...
18 [청계천박물관 문화행사] 6월<문화가 흐르는 청계천의 밤>
19 [청계천박물관] 2023년 하반기 온라인 교육 <톡톡톡 청계천> 참여기관 모집
20 [청계천박물관] 2023년 7월 개방형교육 <우리들의 친구, 청계천박물관>...
21 (책쉼터)도봉구 꽃동네책쉼터,숲속놀이터 독서프로그램(수요일)
22 [산림치유] 서울대공원 산림치유센터, 건강드림(개인용)
23 [산림치유] 서울대공원 산림치유센터, 청춘드림1(65세이상 성인용)
24 [산림치유] 서울대공원 산림치유센터, 청춘드림2(갱년기여성용)
25 2023 곰두리 동물교실 (장애학급 단체)
26 2023 동물해설사와 함께하는 동물사랑! 유치원
27 〔산림치유〕서울대공원 치유의 숲, 하늘빛 마중숲(개인용)
28 〔산림치유〕서울대공원 치유의 숲, 힐링숲(단체용)
29 〔산림치유〕서울대공원 치유의 숲, 행복드림(사회적 배려 계층 단체)
30 (토) 다함께 차차차(茶茶茶) (성인)
31 (토) 다함께 차차차(茶茶茶) (가족)
32 (단체)유아 서당체험
33 [보라매공원] 독소빼고(-) 건강더하기(+) (6월)
34 (토) 어린이대공원 6/3, 6/10, 6/17, 6/24 <6월 어린이 봄 ...
35 (토)신비한 꿀벌교실 꿀벌의 꿀잼생활
36 석호정 성인체험활쏘기
37 석호정 가족활쏘기(어린이 동반가족)
38 (단체)유아 서당체험
39 (개인)유아 서당체험
40 (일) 가족 서당체험
41 (일) 놀이로 배우는 사자소학
42 (일)남산의 숨겨진 역사여행
43 석호정 활쏘기
44 활쏘기 체험교육장(대학생)
45 석호정 활쏘기
46 활쏘기 체험교육장(대학생)
47 (토,일) 남산 둘레길 산행
48 (일) 남산 숲탐정 명탐정
49 (토)남산공원 자연놀이
Name: 서비스명, dtype: object- 이따가 함수 매개변수에 서비스명이 들어가기 때문에 몇 개 복사해서 쓰려고 미리 뽑았다
- 서비스명별 유사도 측정
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2))
info_name_mat = count_vect.fit_transform(data["서비스명"])
info_name_sim = cosine_similarity(info_name_mat, info_name_mat)- 코사인 유사도를 사용하는데 데이터를 벡터로 바꿔서 cosine_similarity()함수를 이용해 유사도 행렬을 생성했다
- 서비스명을 단어별로 분리해서 각 서비스명끼리 비교해서 유사도를 구하는 거라고 한다
특정 정보와 서비스명 유사도가 높은 정보를 얻기 위한 함수 생성
def recommendation(df, sim_matrix, info_name, top_n=10):
# 입력한 정보의 index
target_info_name = df[df["서비스명"] == info_name]
target_index = target_info_name.index.values
# 입력한 정보의 유사도 데이터 프레임 추가
df["similarity"] = sim_matrix[target_index, :].reshape(-1, 1)
# 유사도 내림차순 정렬 후 상위 index 추출
temp = df.sort_values(by=["similarity"], ascending=False)
temp = temp[temp.index.values != target_index] # 자기 자신 제거
final_index = temp.index.values[:top_n]
return df.iloc[final_index]특정 정보와 서비스명별 유사도가 높은 정보 10개 뽑아보기
similar_infos = recommendation( data, name_sim, "[숲해설] 관악구 관악산 계곡숲길 산책, 관악산 계곡숲길 (6월)(화, 오전, 누구나)", 10)
similar_infos[['소분류명', '서비스명','서비스대상','similarity']]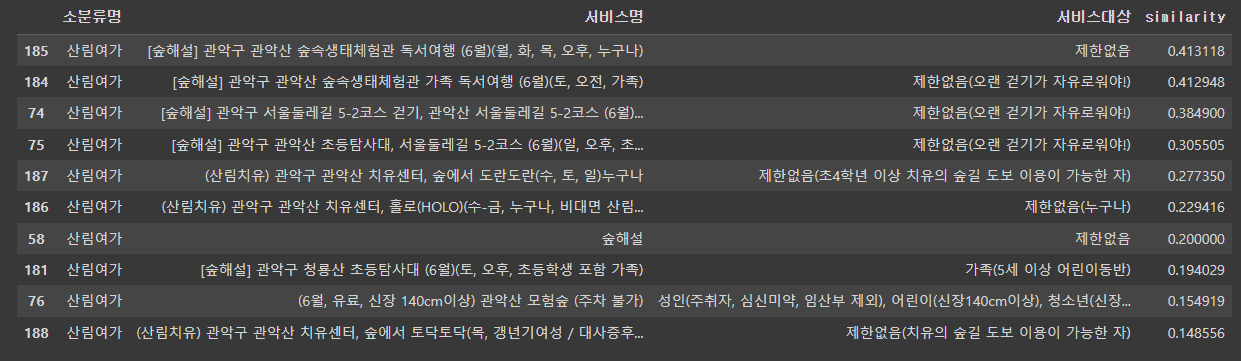
- 이렇게 데이터가 출력된다
- vscode에서 출력하려면 print 써야 하고 colab에서는 그냥 테이블 형식으로 나온다
- 이게 끝은 아니고 이제 우리 프로젝트에 적용시켜서 특정 게시글을 조회했을 때 추천 게시글이 같이 조회되어야 한다
- 그리고 날짜를 기준으로 한 번 더 필터링 할 필요가 있다 이건 다음 게시글에서 정리해보도록 하겠다